

Headscale, the open-source, self-hosted alternative to Tailscale, is designed to be easy to use, light weight, and it utilizes SQLite primarily as its database. Headscale does not support high availability (HA) natively, nor does it support active-active server configuration, however there are options for resilience in production.
In this article, I will explain, as much as I can, my reasoning for the particular architecture I chose which was SQLite, Consul, and automatic failover and the reasons I did not choose alternatives such as PostgreSQL.
Why Not PostgreSQL?
Headscale is built with SQLite as its storage and has built-in assumptions that you have a single-writer database. While PostgreSQL may seem like a natural fit for an HA setup, it creates some serious weight on the project. Here are some main considerations:
Referring to post Feature multiple replicas of headscale instances #2695 of the main contributor of Headscale kradalby:
- Complexity Overhead: Using PostgreSQL requires more overhead for setup, replication, leader-abdication, and potential migration complexities that add even more risk of bugs and operational overhead.
- Headscale Mindset: The Headscale project is intended as lightweight and easy. As the originator of Headscale has stated, adding multi-server sync brings in a lot more complexity and potential for split-brain scenarios. For small to medium size deployments, the added complexity and risk rarely justify the benefits.
SQLite is really the best choice for Headscale because it is easier to use, easier to move around, and stays true to the design goals of Headscale.
The Challenge
Even with SQLite, proper HA is difficult to achieve. If the primary Headscale server goes down, we need to be able to keep the database consistent and have a new leader take over.
SQLite cannot be safely used concurrently, across multiple nodes, in a real master-replicas scheme, we had to consider different options.
It's also worth mentioning that options like Rqlite or other SQLite adapters would also work, although this would require to add a pull request with new strategy for that database connection to the project and add overall complexity.
Lessons from the Headscale Developer
The Headscale developer has communicated that multi-server setups are explicitly not supported for reasons of simplicity and reliability. In summary:
- Full server synchronization across multiple hosts adds complexities to replication and runtime configuration, making debugging problematic.
- Headscale's design assumes network redundancy at the client level, so momentary outages are generally acceptable.
- Simple backup-and-restore is generally a better option than trying to implement HA in a distributed way, so my solution aligns with this philosophy.
I have implemented practical resilience without entirely sacrificing design intent using Consul and replicating SQLite.
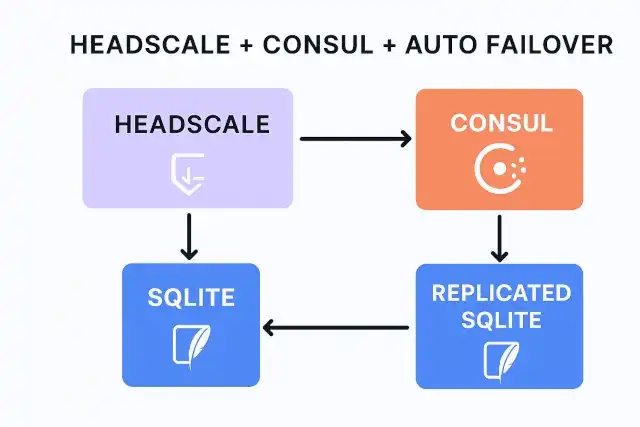
My Solution: Headscale + Consul + Auto Failover
To achieve resilience while respecting Headscale’s SQLite design, I implemented a small project with the following architecture:
Code is available here: https://github.com/gawsoftpl/headscale-litefs-consul
- Primary Headscale Server: Handles all client requests and writes to SQLite.
- Replica Headscale Server: Stays in standby mode, ready to take over if the primary fails.
- Consul for Coordination and Failover: Consul monitors the health of the primary server and automatically elects a new leader if the primary fails.
- SQLite Replication: The SQLite database is continuously replicated by LiteFS to a backup server. Upon failover, the backup server is promoted to primary, and Headscale starts using the replicated database.
This approach provides:
- Automatic Failover: If the master fails, a new server is automatically selected and brought online with the latest database state.
- Minimal Complexity: No need for multiple active Headscale nodes or complex PostgreSQL replication.
- Fast Recovery: Even if downtime occurs, a new server can be auto restored in 15 seconds using the replicated SQLite database.
Disadvantages
- Consistency - It should be remembered that this solution does not ensure consistency.
When primary headscale goes down during write operation, some data may be lost, because
LiteFSfails during sending the data to the replica node. - Replication data encryption - LiteFS replication is not encrypted, because this project was design for fly.io cloud and that platform encrypt traffic by
wireguard. Therefore my solution in production require to add additional network layer to encrypt traffic between LiteFS nodes.
What happens if the coordination server is down?
According to post What happens if the coordination server is down?. If the coordination server (headscale) goes down your Tailscale network will mostly continue to function.
On the other hand, without the coordination server in place:
- New users and devices cannot be added to the network.
- Keys cannot be refreshed and exchanged, meaning that existing devices will gradually lose access to each other.
- Firewall rules cannot be updated.
- Existing users cannot have their keys revoked. source: tailscale.com/kb/1091/what-happens-if-the-coordination-server-is-down
That why 30 seconds of downtime is not a big deal in this scenario. I think master node with 1 replica and auto failover is good enough for most use cases.
A different way to provide high availability is to use Keepalived.
Keepalived can manage virtual IP addresses and can perform automatic failover between Headscale nodes. In this situation, there could be a number of Headscale servers, but only one would be able to server client requests at a time (the one with the virtual IP).
When the primary node dies, Keepalived can move the virtual IP to a backup node, which would be able to serve clients and still appear to be the primary node.
While this makes doing failover at the network level easier, it does not address SQLite's replication problem, for that scenario we have to use LiteFS or LiteStream.
Demo
# Clone repository
git clone https://github.com/gawsoftpl/headscale-litefs-consul
cd headscale-litefs-consul
# Execute docker compose stack
docker-compose up -d
echo "Sleeping for 20s for first election and execute servers..."
sleep 20
Those commands emulate failover of primary and auto switch to another node by consule leader election:
echo "Run status report"
scripts/status.sh
# Get actual leader
leader_name=`scripts/leader.sh`
echo "Actual leader: $leader_name"
# For demo we create users in headscale
docker-compose exec $leader_name headscale users create test test2
# List headscale users, bacause list users saved in primary node
docker-compose exec $leader_name headscale users list
echo "Emulate failover of primary"
scripts/failover-test.sh
# Get new leader
leader_name=`scripts/leader.sh`
echo "Actual leader: $leader_name"
echo "Now headscale should run in second node"
docker-compose exec $leader_name headscale users list
Conclusion
Headscale may not natively support high availability, but reliable failover can still be accomplished without leaving SQLite behind.
By utilizing Consul for leader election and database replication by LiteFS we can be confident that the Headscale service will still work in the event our server goes down.
Additionally, this architecture minimally complicates deployment by avoiding PostgreSQL, is true to the intended use of SQLite in headscale, and provides a respectively robust, and maintainable deployment approach for production builds.












